var str = "中";var charCode = str.charCodeAt(0);console.log(charCode); // => 200132、根据大小判断UTF8的长度
3、补码
既然知道汉字"中"需要占3个字节,那么这3个字节如何得到哪?
这就需要设计到补码,具体补码逻辑如下: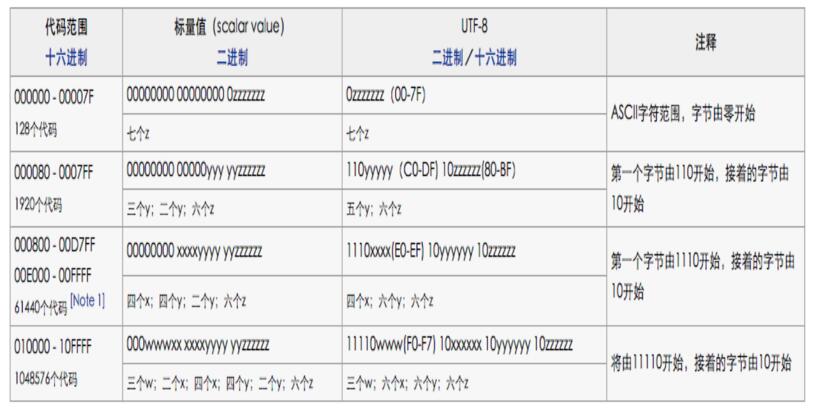
好吧,我知道这个图你们也看不明白,还是我来讲吧!
具体的补位码如下,"x"表示空位,用来补位的。
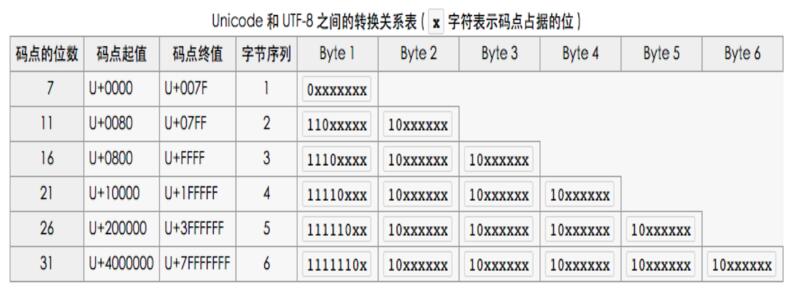
•0xxxxxxx
•110xxxxx 10xxxxxx
•1110xxxx 10xxxxxx 10xxxxxx
•11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
•111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
•1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
warning:有没有发现?补位码第一个字节前面有几个1就表示整个UTF-8编码占多少个字节!UTF-8解码为Unicode就是利用的这个特点哦~
我们先举个简单的例子。把英文字母"A"转为UTF8编码。
1、“A”的charCode为65
2、65位于0-127的区间,所以“A”占一个字节
3、UTF8中一个字节的补位为0xxxxxxx,x表示的是空位,是用来补位的。
4、将65转为二进制得到1000001
5、将1000001按照从前到后的顺序,依次补到1xxxxxxx的空位中,得到01000001
6、将11000001转为字符串,得到"A"
7、最终,"A"为UTF8编码之后“A”
通过这个小例子,我们是否再次验证了UTF-8是Unicode的超集!
好了,我们现在再回到汉字"中"上,之前我们已经得到了"中"的charCode为20013,二进制为01001110 00101101。具体如下:
var code = 20013;code.toString(2); // => 100111000101101 等同于 01001110 00101101然后,我们按照上面“A”补位的方法,来给"中"补位。
var buffer = new Buffer("中"); console.log(buffer.length); // => 3console.log(buffer); // => <Buffer e4 b8 ad>// 最终得到三个字节 0xe4 0xb8 0xad因为16进制是不分大小写的,所以是不是跟我们算出来0xE4 0xB8 0xAD一模一样。
// 将字符串格式化为UTF8编码的字节var writeUTF = function (str, isGetBytes) { var back = []; var byteSize = 0; for (var i = 0; i < str.length; i++) { var code = str.charCodeAt(i); if (0x00 <= code && code <= 0x7f) {byteSize += 1;back.push(code); } else if (0x80 <= code && code <= 0x7ff) {byteSize += 2;back.push((192 | (31 & (code >> 6))));back.push((128 | (63 & code))) } else if ((0x800 <= code && code <= 0xd7ff)|| (0xe000 <= code && code <= 0xffff)) {byteSize += 3;back.push((224 | (15 & (code >> 12))));back.push((128 | (63 & (code >> 6))));back.push((128 | (63 & code))) }}for (i = 0; i < back.length; i++) {back[i] &= 0xff;}if (isGetBytes) {return back}if (byteSize <= 0xff) {return [0, byteSize].concat(back);} else {return [byteSize >> 8, byteSize & 0xff].concat(back);}}writeUTF("中"); // => [0, 3, 228, 184, 173] // 前两位表示后面utf8字节的长度。因为长度为3,所以前两个字节为`0,3`// 内容为`228, 184, 173`转成16进制就是`0xE4 0xB8 0xAD`// 读取UTF8编码的字节,并专为Unicode的字符串var readUTF = function (arr) {if (typeof arr === "string") {return arr;}var UTF = "", _arr = this.init(arr);for (var i = 0; i < _arr.length; i++) {var one = _arr[i].toString(2),v = one.match(/^1+?(?=0)/);if (v && one.length == 8) {var bytesLength = v[0].length;var store = _arr[i].toString(2).slice(7 - bytesLength);for (var st = 1; st < bytesLength; st++) {store += _arr[st + i].toString(2).slice(2)}UTF += String.fromCharCode(parseInt(store, 2));i += bytesLength - 1} else {UTF += String.fromCharCode(_arr[i])}}return UTF}readUTF([0, 3, 228, 184, 173]); => "中"另外一种将中文解析得到UTF8字节码的方法var str = "中";var code = encodeURI(str);console.log(code); // => %E4%B8%AD有没有发现得到了一个转义后的字符串,而且这个字符串中的内容和我之前在上面得到的字节码是一样的~~~。
var codeList = code.split("%");codeList = codeList.map(item => parseInt(item,16));console.log(codeList); // => [228, 184, 173]如此简单,有木有~~~
var codeList = [228, 184, 173];var code = codeList.map(item => "%"+item.toString(16)).join("");decodeURI(code); // => 中好了,到这里本文也就介绍完UTF8的编码了。