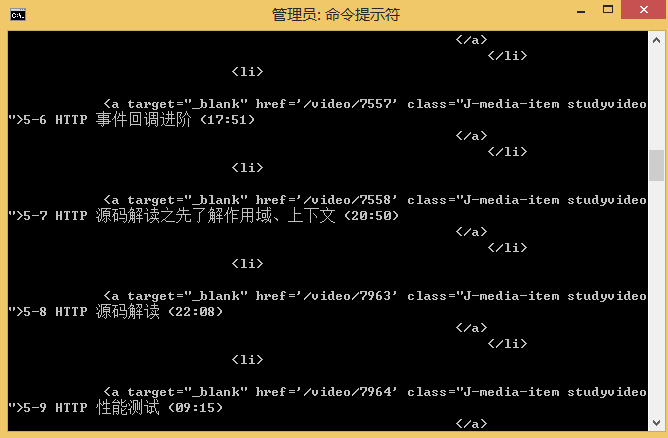
2、分析后的数据,提供的示例为案例实现的例子。
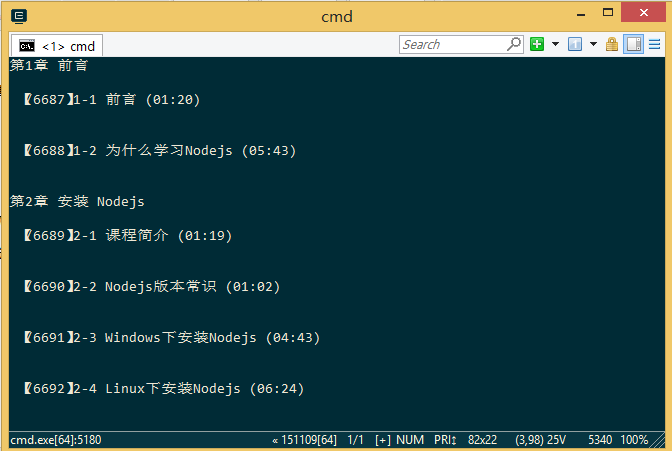
爬虫初探源码分析
var http=require("http");var cheerio=require("cheerio"); var url="http://www.imooc.com/learn/348"; /****************************打印得到的数据结构[{ chapterTitle:"", videos:[{title:"",id:"" }]}]********************************/function printCourseInfo(courseData){ courseData.forEach(function(item){var chapterTitle=item.chapterTitle;console.log(chapterTitle+"
");item.videos.forEach(function(video){ console.log(" 【"+video.id+"】"+video.title+"
");}) });}/*************分析从网页里抓取到的数据**************/function filterChapter(html){ var courseData=[];var $=cheerio.load(html); var chapters=$(".chapter"); chapters.each(function(item){var chapter=$(this);var chapterTitle=chapter.find("strong").text(); //找到章节标题var videos=chapter.find(".video").children("li"); var chapterData={ chapterTitle:chapterTitle, videos:[]}; videos.each(function(item){ var video=$(this).find(".studyvideo"); var title=video.text(); var id=video.attr("href").split("/video")[1];chapterData.videos.push({title:title,id:id })}) courseData.push(chapterData); });return courseData;} http.get(url,function(res){ var html="";res.on("data",function(data){html+=data; })res.on("end",function(){var courseData=filterChapter(html);printCourseInfo(courseData); })}).on("error",function(){ console.log("获取课程数据出错");})参考资料: